
We need to talk about dbt
a love-letter to my favourite command line tool


This is a love letter, not a hate letter. I am, and have been, a dbt lover for a long time. I am not a dbt-skeptic. I don’t like doing hot-takes and take-downs of companies and the things people work on. This is not that. This is the culmination of many days and nights spent thinking about a product I love and how I feel less and less connected to it as time goes on. I want to rekindle that love.
dbt has made itself a core part of the Modern Data Stack ™ (whatever that may be). Analysts love using it, data tools all want to integrate with it, and it’s seen explosive growth in the past few years. But with that growth, something feels off in the state of data.
The Devil’s Bargain of Venture Funding
First, a brief history of dbt Labs and Fishtown Analytics. I still remember their pivot from a consulting company that happened to have an open-source tool, to a venture-backed startup. It was April 2020, almost exactly 2 years ago. There were 5,000 people in the Slack Community. It was an exciting time to be in data. Here was this company helping people like me create models in the warehouse in a way that felt as powerful as how software engineers built their products. It was scrappy, hacky, but it was cool. We had a CLI, we had git repos, we even had tests!

7 months later, in November of 2020, dbt announced a 30-million dollar series-B. They now had 3,000 companies using dbt every week.
Getting very in-the-weeds: we’re planning on being at roughly 60 people and 15 engineers by EOY this year and about 110 people and 35 engineers by EOY 2021. Even with that significant increase in burn, we now have runway through EOY 2024—4 full years.
8 months later, in June 2021, they announced a $150m series-C. With 5,500 companies using dbt, and 15,000 people in their Slack, dbt continued to grow at a rapid pace.
3. Raise more money and build product fast. Recognize that our space is heating up and this forces us to accelerate our ability to build differentiated products
We chose option #3. We believe that our independence is critical as we chart the course for the future of dbt, the dbt Community, and for the practice of analytics engineering.
The most recent round was in February 2022, with $222m in funding, 9,000 companies, and 25,000 people in their Slack, not to mention Coalesce.
In the last 2 years, dbt has had four rounds of funding. With funding comes pressures to generate revenue and demonstrate growth. Rightly, investors want returns on their capital. I don’t begrudge dbt for raising money or for pursuing profits, they aren’t, after all, a charity. They are a company, and their duty is to generate revenue for their shareholders, some of whom are their employees.
But funding comes with strings attached, and so I present this history to set the context for the problems with dbt as I see them today, and they fall into three categories: community, core, and cloud.
The Community Problem
A community of 8,000 people is a very different beast than a community of 30,000. With that growth has come two issues: volumes, and vendors.
dbt Slack has grown so big it has become hard for me to follow, and I’ve been a very active member of the Slack community in my two years as a part of it. I’ve live-tweeted Coalesce, made memes, responded to questions, asked my fair share, and tried to keep up with the great content people shared.
But these days, I barely check the Slack community. Part of the problem is just one of sheer scale. Many channels that could be interesting have become troubleshooting catch-alls for people with technical questions.
One of the biggest problems with the community however is that it’s now seen largely as a content-distribution channel by data vendors. #i-made-this and #i-read-this were initially created for the community to share what they’re working on, but it’s since become a dumping ground for content-marketing.
In January of this year, there was a discussion around creating a vendor content channel, but that channel has exactly one post in it, and no real moderation exists outside of that channel.
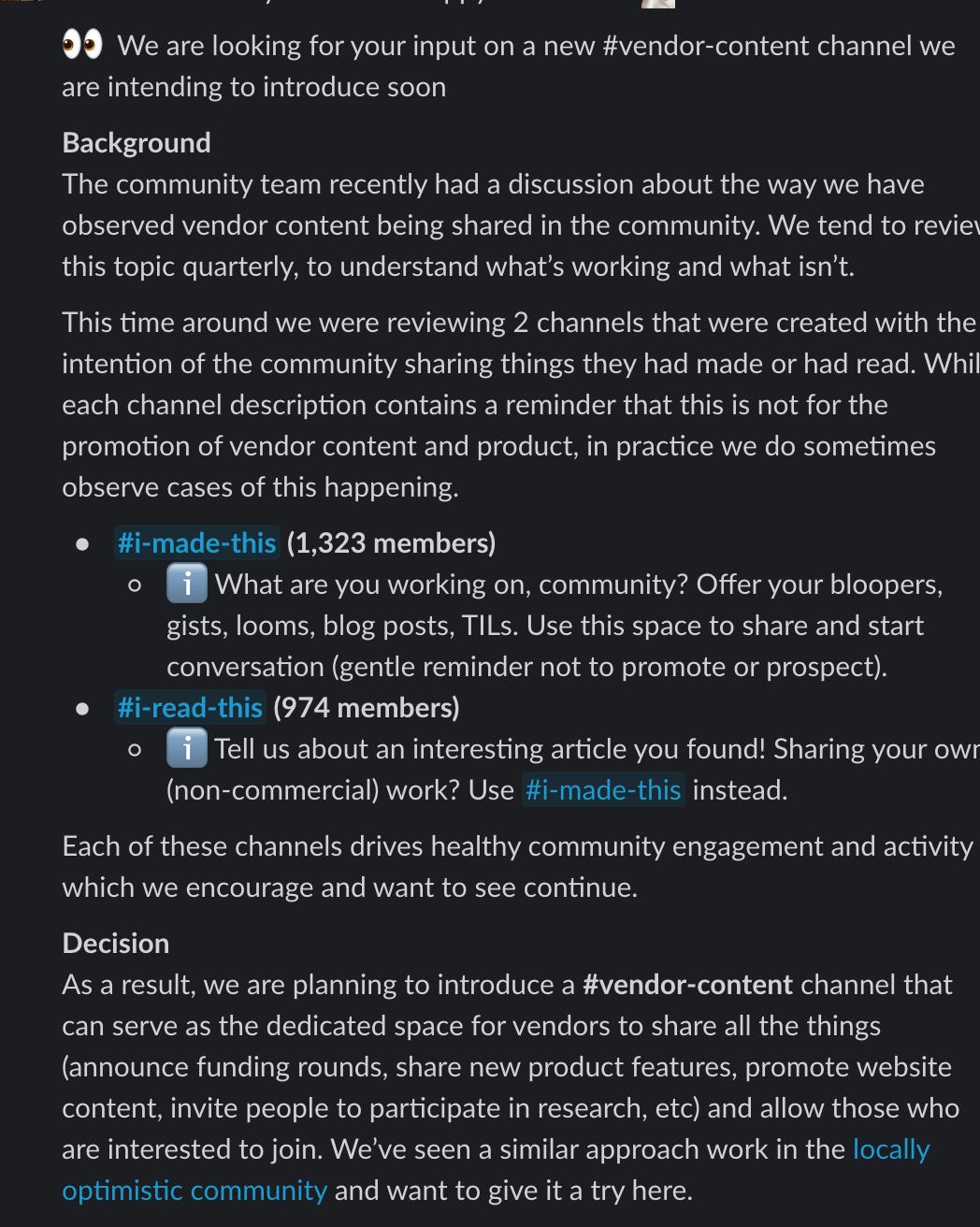
Many threads that do start as genuine questions become lead-generation funnels for data vendors trying to push their product.
With that said, there is work being done. The Analytics Engineering guide holds promise, and I hope to see dbt continue to curate great content from the community and bring it up to their website to make discovering knowledge easier. dbt Discourse holds a wealth of information and I still stumble upon answers to my questions in there, although it’s hard to keep it top of mind when I want to learn something new. I’m especially looking forward to more practitioner-led content on the dbt Developer Blog, though I hope they realize you can’t just wish content into existence, you must find people doing great work and help them writing it.
The Core Problem
dbt Core, or what I used to just call the CLI, is where my biggest hopes and regrets lay. To this day, I can’t give dbt a file name and hope it figures out what I mean, but instead I still have to remove the .sql at the end. Small gripes.
I have bigger gripes though. The biggest one is the lack of transparency and communication from dbt’s leadership about their vision for core. Where’s the love it used to get? What’s the plan for development? Is there one? Has all development on core been pushed aside in favor of cloud and metrics? My biggest issue here is that I just don’t know.
There’s the Analytics Engineering Roundup, which could be a perfect venue for discussing the future of dbt. Instead, it has largely become a place for the same male-dominated voices to receive a platform. To be fair, with the addition of Anna Filippova, Roundup has gotten a lot better, but instead of linking to the David and Benn show, or discussing the future of capitalism with ventures and CEOs, what if we had insight into what the vision of dbt is for practitioners from the CEO of dbt? I long for that.
A great example of something promising that I still hold out hope for is dbt Exposures. A nice first step in helping expand lineage beyond just the models that dbt creates but right down to the artifacts that depend on those models. Imagine a world where you could tell dbt to refresh all models that feed into an operational use case like syncing data into Salesforce, so that your syncs use the freshest of fresh data. The problem is that exposures are manual, and there’s no clear way for vendors to integrate with dbt exposures.
This Github discussion from October 2020 hasn’t really given us much insight, and a few relatively simple features have been all but forgotten. It could be that dbt is working hard on building out a great experience here, but I’d have no way of knowing it.
Macros are the illegitimate step-child of dbt and Python, a jinja-powered hot mess of untestable code, yet they remain the predominant way in which any logic outside of SQL is done in dbt. Is this the future of data analysis, or can we hope for something better? If Snowflake can run Python, why can’t dbt?
Ask any data vendors about how they integrate with dbt over a few drinks and you will hear some stories. For an open-source CLI, it’s exceptionally hard to integrate well with it. Something as seemingly simple as ‘getting the name of all models without running the entire project against a warehouse’ is actually impossible. No one wants to parse the undocumented hell that is manifest.json, but it’s our only choice.
Given a dbt project of sufficient size, odds converge to 1.0 that two tables will want the same name, yet namespaces are not supported in refs, but they are in sources. I wish I understood why.
The year is 2022, and I still need to run dbt before I can catch a syntax error. Imagine a world where VS Code or vim could leverage a dbt language server that catches errors before you run them. Imagine a world where dbt created VS Code plugins and we didn’t depend on the kindness of strangers.
2 years ago I really felt that dbt cared about the developer experience. Everything they did showed that was true. 2 years later, I don’t feel that way. That doesn’t mean that they don’t care, I know there are many people at dbt working hard on these problems, and thinking carefully about them. But that doesn’t change how I feel, and I really wish that weren’t the case.
The Cloud Problem
dbt Cloud is a really bad experience. I hate saying this, but it’s also so universally known that I don’t think it is even controversial to say. In the end, it’s nothing more than a text editor with some syntax highlighting. Loading it is exceptionally slow, it has almost no awareness of the dbt ecosystem, and the interface is so confusing that I find it impossible to recommend to people learning dbt, which is so painful for me.
This is the real problem with dbt today, I think. I want an ecosystem that is so painless, and so easy, that I can take someone who wants to learn dbt, give them a tool, a 10-minute intro, and have them start building models. This is my dream.
dbt Cloud does not yet offer this. I’ve been burned many times by it. If I forget to switch to a branch before starting work, I’ll often lose the work I’ve done. It takes so long just to start writing code that I’ll end up closing the window and switching to the terminal instead. I still don’t know why it isn’t aware of the dbt deps command natively, and why it can’t just install them for me.
Imagine a world where dbt Cloud was natively aware of the dbt metadata and could switch seamlessly between model building, and model documentation. Imagine a world where I didn’t have to generate the documentation every time I wanted to view it, but where dbt Cloud knew to generate documentation for me as my models changed.
I really, really want dbt Cloud to be a great experience for people, especially people who are new to the analytics engineering ecosystem. Python and git are hard enough, we should be able to abstract that pain away in a simple, intuitive IDE that can help people get started with model building right away. Instead I have to explain so many caveats and gotchas with cloud, that I might as well teach them how to use VS Code and the command line instead.
Outside of the user experience, there’s also just the raw features. We still don’t have web hooks available publicly. The Metadata API is essentially undocumented. I still don’t know how to use it, or why I would. Much like exposures, Metadata, feels likes one of those things dbt developed and then forgot about. There’s so much hope and promise here, I just wish I knew that dbt cared about it as much as I do.
Who is dbt for?
I think in the end, my issues with dbt might simply be a consequence of the fact that maybe dbt isn’t for me anymore. With large funding comes a demand for large customers, and large customers care more about the features on their roadmap than I do. Maybe it’s true that there’s not a lot of money in developing an autocomplete CLI, when Enterprise customers want customer-managed keys and audit-logging. Maybe there’s less incentive to make dbt compile faster than there is to make dbt Cloud work better for projects with thousands of models.
Maybe the real source of these issues is just a lack of clarity or transparency. If so, that’s an easier fix, but more and more it starts to feel like the former rather than the latter. Maybe this is just what happens to all good software you love. I don’t know.
I hope I’m wrong. I hope there’s actually amazing work being done behind the scenes, behind closed doors, and in a few months time I’ll be amazed at the volume of developer-focused features and quality-of-life improvements that makes writing dbt models feel as exciting as it did back in 2020. It’s been a long two years for everyone, anything is possible. Here’s hoping.