
Deep Dive: What the Heck is Entity Resolution
or record linkage, or identity mapping, or data matching.

Entity Resolution, Identity Mapping, Record Linkage, Data Matching, and Record Matching. The names are many, but the concept is deceptively simple. In this Deep Dive, we'll look at Entity Resolution and some of its core components.
If you prefer video, I gave a talk on Entity Resolution at dbt's office hours 2 years ago. If you prefer books, there's no other book I'd recommend more than Peter Christen's Data Matching. If you prefer my Substack, you’re in the right place.
Let's dive in.
What is Entity Resolution?
Entity resolution is all about combining multiple records of things. There are two parts to entity resolution: first is the entity, and second is the record of that entity in some database.
The entity can be anything from a person to a company to a physical product. I'll use companies as examples here, but the underlying logic applies to any entity you want to dedupe.
A record of that entity might exist in a spreadsheet, a database, or across multiple databases.
What's important is that there is no unique identifier representing that entity. If you were trying to dedupe people and had their Social Security Number or another national identification number, then the problem would be relatively easy. However, absent a single unique indicator, if we want to match or dedupe these records, then we need a way to resolve them to a single entity: hence, entity resolution.
An Illustrative Example
Let's say you work at a small B2B company with data in various systems of record: your production database, your Salesforce instance, and several spreadsheets of data with leads captured at various events.
Anyone can sign in to your product by providing their company name and email address. Your Salesforce instance has accounts with company names, locations, websites, and contact information. The leads spreadsheet has similar information hand-captured by a person running the event.
It might look something like this:

How do you decide whether or not these different records are part of the same underlying entity? You might keep it simple and decide that two entities are the same if they share the same website, but even websites change over time. While a simple solution may be sufficient, you're entering the realm of entity resolution if you're not satisfied with that.
The 5 Steps to Entity Resolution
This deep dive will go through the five keys to entity resolution. There is much more nuance and depth beyond this post, but this should be enough to get us started.
Pre-processing
Indexing
Comparing
Classifying
Merging
Pre-processing
Before we embark on our journey, starting with a good foundation is essential. As much as possible, we want to clean our underlying data. Everything from trimming extra whitespaces to lowercasing all the characters, removing stop-words, or even stemming and lemmatizing is possible here. The specifics are highly context-dependent, and always an iterative process. As you perform these steps on data samples, your appreciation for what you need to do to improve the quality of matches will increase, and you will refine your pre-processing.
You'll want to abstract the pre-processing steps as much as possible. Regular expressions can be convenient here, and knowing how to use them correctly can increase the performance of your system. For example, in Python, compiling your regular expression before using them will improve performance, and taking advantage of a cache to avoid repetitive computations can save significant time as you process millions of rows.
If you're using dbt, macros are helpful to reduce code duplication, and as you find incremental improvements, you only have to apply them in one place.
Some common pre-processing steps I've seen are:
Making everything lowercase and removing whitespaces
Splitting an email into user and domain
Cleaning company names to remove stop words such as ... Inc. ... LLC, The .., A ...
Converting words such as null, na, n/a to actual NULLs
Filtering out demo/test/internal users
Parsing and cleaning websites and addresses

Example Macro for cleaning company names using Regular Expressions

Indexing and Blocking
Once you have cleaned your data, the next step is to index the data to improve performance. Consider this example: you have 100,000 records in Database A and 10,000 in Database B, with no common indicator. How many comparisons are you performing if you look at the website and name?
The formula for this is (m * n) * p, where m and n are the number of records in each table, and p is the number of indicators. So we get 2,000,000,000 or two billion comparisons if we do the math, and that's on relatively small tables. You can see how this will not scale beyond a million records.
Our only hope is to reduce the search space. Of course, we can't compare every single record against each other, but we can compare within a subset with a three-step process of blocking, indexing and reverse-indexing.
Blocking is taking your entire record and chunking it into smaller blocks to avoid comparing every value with every other value. So the obvious question is, how do you block records together if you need to know how to match them?
In the simplest example, you might block by comparing records from the same country, state, or zip code, or you could look at the first letter of a name.
There are also algorithmic options. If your entities are names of people or companies, you could use various functions to reduce the search space by compressing information.
Soundex is an example of an algorithm, developed a century ago for use on names. It encodes similar-sounding names, can be used as a blocking key and is supported in many data warehouses, including Snowflake.
select
soundex('pedram') as pedram,
soundex('pedrum') as pedrum,
soundex('peter') as peter,
soundex('pedro') as pedro
> PEDRAM PEDRUM PETER PEDRO
p365 p365 p360 p360
You can see that Peter and Pedro are blocked together, and Pedram and Pedrum are as well.
There are many different blocking techniques, and this survey paper reviews many of them, but the principle behind them is essentially the same.
You could also use multiple blocking keys to improve accuracy. For example, you might run Soundex on first and last names and compare similar blocks across either first or last names. But, of course, the trade-off is always between performance and accuracy.
Once you've defined your blocking function, you can apply it to every database record. This step is called indexing. For example, below, suppose we ran every name through a Soundex function. Each record has a Soundex associated with it.
Record 1 - D130
Record 2 - D130
Record 3 - F235
Record 4 - F235
Record 5 - D130
Next, we combine all records with the same blocking key into a subgroup for comparison purposes. To do this, we rely on a reverse index: for every blocking key, identify all the rows that belong to that block.
D130: {1, 2, 5}
F235: {3, 4}
In doing so, we can efficiently work on a block of similar records, and can even distribute this work in parallel. Once we have our reverse index, we are ready to proceed to Comparing.
Comparing and Classifying
I group comparing and classifying into one topic here because they are interrelated. Comparing is the act of summarizing the similarity between two records, and classifying is the act of deciding whether two records are 'similar enough.'
There are many ways to compare two records. First, you can look at equality for any column, which is the most straightforward comparison.
if(a.name = b.name) then 1 else 0
On strings, you can look at how similar they are using similarity functions such as the edit distance or the Jaro-Winkler similarity score.
You can compare numbers by absolute or percent differences. You could look at dates, ages, times, or geographies.

To classify, you can average the results from above to generate a score for each record. You can weigh individual fields, for example, giving greater weight to the last name over the first name. You might decide on a threshold that balances false positives and negatives or lean on machine learning or other more advanced techniques for classification.
There's no perfect way to compare and classify, but the goal is always the same: to create a list of tuple pairs of matched records.
One complication: records A and B might match, and records B and C might match, but records A and C might not. Therefore after matching, you need to process all the records to perform a merge.
For example, suppose you have seven records and have compared them with some arbitrary matching formula. You end up with the following tuple pairs of matched records.
{1, 2}{3, 4}{5, 6}{1, 7}{2}{6, 5}{7, 5}
If we graphed these pairs, it would look something like this:
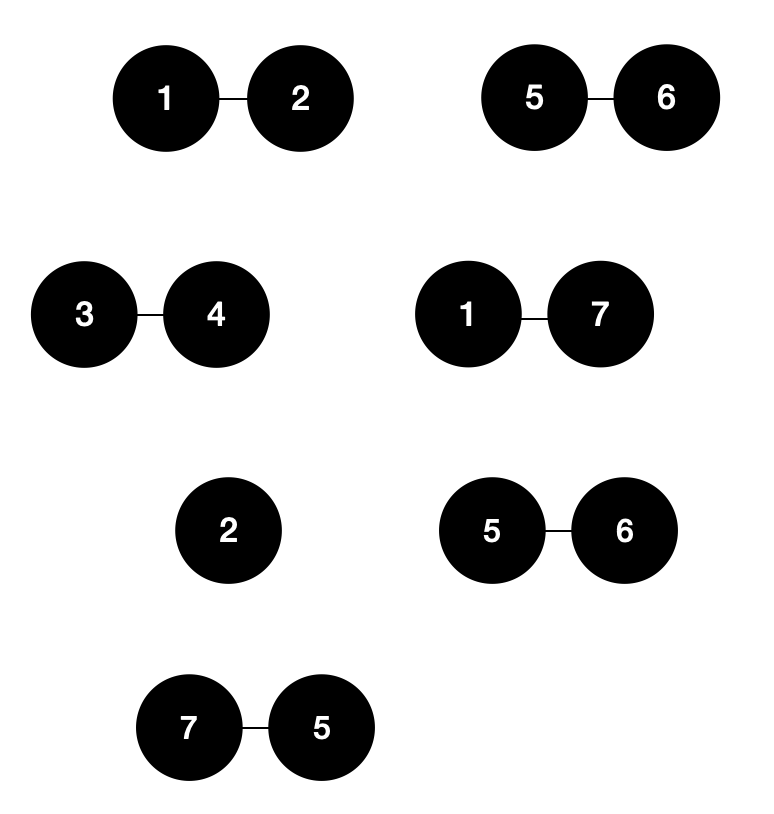
However, since some pairs share a common record, we need to connect these pairs. So how do we do that? We use the aptly named connect components algorithm!
Using this algorithm, we reduce the above example to two distinct entities:
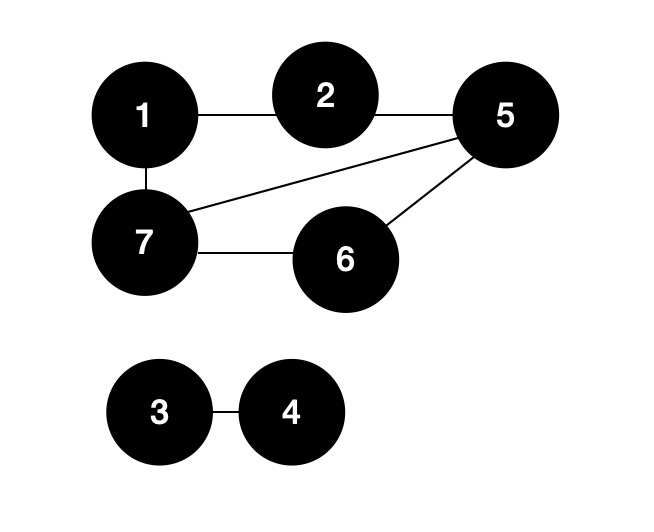
We identified two entities using those seven records and are tantalizingly close to the end: our last step is merging records.
Merging Records
Given two or more records that refer to the same underlying entity, we must decide how to merge the information. For example, if the names are different, what do we keep?
The first approach is randomly picking one as the master record and using all the information in that one. This approach is the easiest and least subtle, but it can often be sufficient for our needs.
A better approach is to rank sources on a per-record or per-field basis. So, for example, we might pick first and last names from Database A but use addresses from Database B.
Both methods result in a loss of information, so another approach is called the Union Set. Essentially we keep all distinct elements across all records. At the very least, we want to keep the union set of table primary keys for better debugging.
Suppose Database A has a record with primary key 123 and Database B has a record with primary key 456; we might merge these two records such that the primary key field is now {A: 123, B: 456}
Another option is to use ranges. If we are merging company information and have two different sources for the number of employees, we might include them as a range. If Record A had 100 employees, Record B had 250 employees, and Record C had 175, we might merge these two records as [100, 250].
You can imagine many other ways to merge records, but the goal is to preserve the right level of detail for your particular use case.

Wrapping Up
Once merged, your work is largely done. You have created a set of candidates, classified them, linked records, and merged them together, but your journey has just begun. There is much more in this field to learn. Decisions on blocking keys, classification methods, and supervised/unsupervised learning, just to name a few.
You may also want to check out some libraries and products in this space, such as the Python Record Linkage library and the many available research papers on this topic.
Hope you enjoyed this deep dive, if there’s any topic you’re interested in, reach out and let me know!